lmgrep Text Analysis

TL;DR
lmgrep provides an easy way to play with various text analysis options.
Just download the lmgrep binary, run it with --only-analyze, and observe the list of tokens.
echo "Dogs and CATS" | lmgrep \
--only-analyze \
--analysis='
{
"tokenizer": {"name": "standard"},
"token-filters": [
{"name": "lowercase"},
{"name": "englishminimalstem"}
]
}'
# => ["dog","and","cat"]
Text Analysis
The Elasticsearch documentation describes text analysis as:
the process of converting unstructured text into a structured format that’s optimized for search.
Therefore, to learn how the full-text search works it is important to understand how the text is, well, analyzed.
The remainder of the post focuses on how text analysis is done in Lucene which is the library that powers search engines like Elasticsearch and Solr, and what lmgrep provides to analyze your text.
Lucene
Text analysis in the Lucene land is defined by 3 types of components:
- list of character filters (changes to the text before tokenization, e.g. HTML stripping, character replacement, etc.),
- one tokenizer (splits text into tokens, e.g. at whitespace characters),
- list of token filters (normalizes the tokens, e.g. lowercases all the letters).
The combination of text analysis components makes an Analyzer.
You can think that an analyzer is a recipe to convert a string into a list of tokens1.
lmgrep
lmgrep is a search tool that is based on the Lucene Monitor library.
To do the full-text search it needs to do the same thing that likes of Elasticsearch are doing: to analyze text.
lmgrep packs many text analysis components.
Also, it provides a list of predefined analyzers.
Nothing special here, the same battle tested and boring Lucene components that gets the job done2.
However, lmgrep provides one clever twist to text analysis:
a way to specify an analyzer using plain data in JSON, e.g.:
echo "<p>foo bars baz</p>" | \
lmgrep \
--only-analyze \
--analysis='
{
"char-filters": [
{"name": "htmlStrip"},
{
"name": "patternReplace",
"args": {
"pattern": "foo",
"replacement": "bar"
}
}
],
"tokenizer": {"name": "standard"},
"token-filters": [
{"name": "englishMinimalStem"},
{"name": "uppercase"}
]
}
'
# => ["BAR","BAR","BAZ"]
Again, nothing special here, read the docs3 of an interesting text analysis component, e.g.
character filter patternReplace,
add its config to the --analysis, and apply it on your text.
Conceptually it is very similar to what Elasticsearch or Solr are providing: analysis part in the index configuration JSON in Elasticsearch, and Solr Schemas in XML.
lmgrep analysis component has this structure:
{"name": "COMPONENT_NAME", "args": {"ARG_NAME": "ARG_VALUE"}}
Notes:
- some components, e.g.
stoptoken filter, expect a file as an argument. To support such componentslmgrepbrutally patched Lucene to load data from arbitrary files while preserving the predefined analyzers with, e.g. their custom stop-word files. - when a predefined analyzer is provided for text analysis then all other analysis components are silently ignored.
- predefined analyzers do not support the
argsas of now, just thename. lmgrepas of now doesn’t provide a way to share components between analyzers.
That is pretty much all there is to know about how lmgrep does text analysis. Try it out and let me know how it goes.
--only-analyze
I like the Elasticsearch’s Analyze API. It allows me to look at the raw tokens that are either stored in the index or produced out of the search query.
To make debugging of lmgrep easier I wanted to expose something similar to Analyze API. The --only-analyze flag is my humble attempt to do that.
When the flag is specified then lmgrep just outputs a list of tokens that is produced by applying an analyzer on the input text, e.g.:
echo "the quick brown fox" | lmgrep --only-analyze
# => ["the","quick","brown","fox"]
Implementation
The machinery under the --only-analyze works as follows:
- one thread is dedicated to read and decode the text input (either from STDIN or a file),
- one thread is dedicated to write to the STDOUT,
- the remaining CPU cores can be used by a thread pool that analyzes the text (thanks to Lucene Analyzer implementation being thread-safe).
On my laptop lmgrep analyzes ~1GB of text in ~11 seconds and consumes maximum 609 MB of RAM. It should result in ~200 GB of text per hour. IMO, not bad. Of course, the more involved the text analysis is the longer it takes.
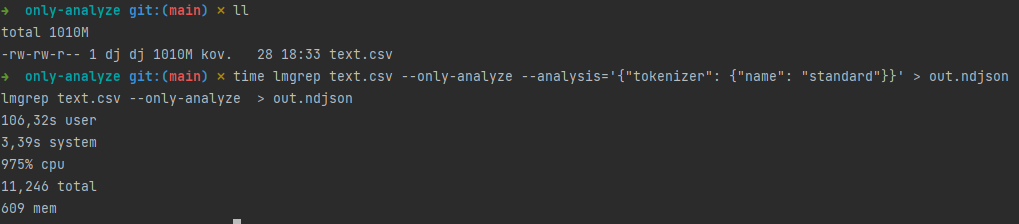
Note that the output of --only-analyze has the same order as the input. IMO, it makes the output a bit easier to understand. However, preserving the order limits the throughput. It is because the time and resources needed to analyze an individual piece of text can vary greatly, and the required coordination introduces some overhead.
Consider an example of analyzing the text attributes of a book: assume that the first line sent to lmgrep is the title of the book, the second line contains a full text of the book, and the third line is the summary. The title is relatively small, it is quickly analyzed and immediately written to STDOUT. The summary is a bit longer but still many times smaller than the body. To preserve the order lmgrep (before writing the tokens of the summary to STDOUT) waits for the analysis on the body to be finished and written to STDOUT and only then tokens of the summary are written out.
Notes:
- the
--explainflag is coming tolmgrep; - the output lines are valid JSON (
jqis your friend); - the positional arguments for
--only-analyzeare interpreted as files and when present then STDIN is ignored.
Interesting Bit
One thing that constantly frustrates me with Elasticsearch’s Analysis API is that I can’t specify custom char filters, tokenizer, and token filter directly in the body of the request to the Analysis API.
To observe the output of text analysis that involves custom text analysis components first I have to create an index with an analyzer and then call Analyze API that involves that index. lmgrep avoids this pain point by allowing to declare text analysis components inline.
Post Script
All this analyzer construction wizardry is possible because of Lucene’s AbstractAnalysisFactory class and features provided by its subclasses. The CustomAnalyzer builder exposes methods that expects a Class as an argument, e.g. addCharFilter. The trick here is that, e.g. the class TokenFilterFactory provides a method availableTokenFilters that returns a set of names of token filters and with those names you can get a Class object that can be supplied to CustomAnalyzer builder methods.
The discovery of available factory classes is based on the classpath analysis, e.g. fetching all classes where name matches a pattern like .*FilterFactory and are subclasses of a TokenFilterFactory. However, for the reasons that were beyond my understanding, when I created my own TokenFilterFactory class it was not discovered by Lucene ¯\_(ツ)_/¯.
Yeah, great, but lmgrep is compiled with the GraalVM native-image which assumes closed-world and throws the dynamism of the JVM out the window. How then does exactly this TokenFilterFactory-thing-class discovery works? Yes, Native images must include all the classes because at run-time it cannot create classes, but it can be worked around by providing the configuration with the classes that are going to be used at run-time, and those interesting classes can be reflectively discovered at run-time. lmgrep relies on the Java classes being discoverable at compile-time where the reflection works as expected.
To instruct the native-image to discover the Java classes from Clojure code you can specify the class under the regular def because to the native-image defs look like constants and are evaluated at compiled-time. So, if lmgrep misses some awesome Lucene token filter, all it takes is to add it to the hashmap under a def.