lmgrep - Lucene Based grep-like Utility
 Grep with Lucene
Grep with LuceneTL;DR
What if grep supported the functionality of a proper search engine like Elasticsearch without a need to install any servers or index the files before searching?
lmgrep aims to provide you just that.
It is installed as just one executable file without any dependencies, provides a command-line interface, starts-up instantly, and works on macOS, Linux, and, yes, even Windows.
See the source code here.
My motivation
Have you ever wished that grep supported tokenization, stemming, etc, so that you don’t have to write wildcard regular expressions all the time? I’ve also shared that question and on a one nice day, I’ve tried to scratch that itch by exposing the Lucene query syntax as a CLI utility. lmgep is the result of my effort. Give it a try and let me know how it goes.
Full-text Search vs. grep
I’m perfectly aware that comparing Lucene and grep is like comparing apples to oranges. However, I think that lmgrep is best compared with the very tool that inspired it, namely grep.
Anyway, what does grep do? grep reads a line from stdin, examines the line to see if it should be forwarded to stdout, and repeats until stdin is exhausted1. lmgrep tries to mimick exactly that functionality. Of course, there are many more options to grep but it is the essence of the tool.
Several notable advantages of lmgrep over grep:
- Lucene query syntax is better suited for full-text search;
- Boolean operators allow to construct complex, well-designed queries;
- Text analysis can be customized to the language of the documents;
- Fuzzy text searches;
- Flexible text analysis pipeline that includes, lowercasing, ASCII-folding, stemming, etc;
- regular expressions can be combined with other Lucene query components;
- Search matches can span multiple lines, i.e. search is not line-oriented.
Several notable limitations of lmgrep when compared to grep:
grepis faster when it comes to raw speed for large text files;grephas a smaller memory footprint;- Not all options of
grepare supported;
Why Lucene?
Lucene is a Java library that provides indexing and search features. Lucene has been more than 20 years in development and it is the library that powers many search applications. Also, many developers are already familiar with the Lucene query syntax and know how to leverage it to solve complicated information retrieval problems.
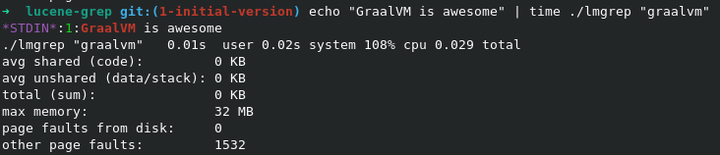
However powerful Lucene is, it is not well-suited for CLI application. The main problem is the startup time of JVM. To reduce the startup time I’ve compiled lmgrep with the native-image tool provided by GraalVM. In this way, the startup time is around 0.01s for Linux, macOS, and Windows.
How does lmgrep work?
lmgrep by default expects two parameters: a search query and a GLOB pattern (similar to regexp) to find files to execute lmgrep on. I assume that the dear reader doesn’t want to be tortured by reading the explanation on how the file names are being matched with GLOB, so I’ll skip it. Instead, I’ll focus on explaining how the search works within a file.
lmgrep creates a Lucene Monitor (Monitor) object from the provided search query. Then text file is split into lines2. Each line of text is passed to the Monitor for searching. The Monitor then creates an in-memory Lucene index with a single document created out of the line of text. Then the Monitor runs the search query on that in-memory index in the good ol' Lucene way3. lmgrep takes the hits, formats them, and sends results to STDOUT. That is how lmgrep does the full-text search.
The overall searching approach is similar to the one of Percolator in Elasticsearch. lmgrep just limits the number of stored search queries to one and treats every text line as a document. A cool thing compared with the Percolator is that lmgrep provides exact offsets of the matched terms while Elasticsearch does not expose offsets when highlighting.
The described procedure seems to be somewhat inefficient. However, the query parsing for all the lines (and files) is done only once. Also, the searching itself is efficient thanks to Lucene in general and when queries are complicated thanks to the Presearcher of the Lucene Monitor in particular. Presearcher extracts terms from the search query and if none of these terms are in the index then a full query is not executed at all. Of course, many optimizations can be (and will be) implemented for lmgrep such as batching of the documents. In general, the performance is limited by the Lucene Monitor.
What about the text analysis pipeline? By default, lmgrep uses the StandardTokenizer to tokenize text. Then the tokens are passed through several token filters in the following order: LowerCaseFilter, ASCIIFoldingFilter, and SnowballFilter which is given the EnglishStemmer. The same analysis pipeline is used for both the indexing and querying. All the components of the analysis pipeline are configurable via CLI flags, see the README. However, the order of the token filters, as of now, is not configurable. Moreover, various filters are not exposed at all (e.g. StopwordsFilter, or WordDelimiterGraphFilter, etc.). Supporting a more flexible analysis pipeline configuration is left out for future releases. The more users the tool has the faster new features will be implemented ;)
Prehistory of the lmgrep
Almost every NLP project that I’ve worked on had the component called dictionary annotator. Also, the vast majority of the projects used Elasticsearch in one way or another. The more familiar I’ve got with Elasticsearch I’ve got, the more of my NLP workload shifted towards implementing it inside Elasticsearch. One day I’ve discovered a tool called Luwak (a cool name isn’t it?) and read more about it. It kind of opened my eyes: the dictionary annotator can be implemented using Elasticsearch and the dictionary entries can be expressed as Elasticsearch queries. Thankfully, Elasticsearch has Percolator that hides all the complexity of managing temporary indices, batching search requests, etc.
Then I was given was an NLP project where one of the requirements was to implement data analysis using AWS serverless stuff: Lambda for text processing and Dynamo DB for storage. Of course, one of the required NLP components was a dictionary annotator. Since Elasticsearch was not available (because it is not serverless) I still wanted to continue working with dictionary entries as search queries, I’ve decided to leverage the Luwak library. From experiences of that project, the Beagle library was born. lmgrep is loosely based on Beagle.
When thinking about how to implement lmgrep I wanted it to be based on Lucene because of the full-text search features. To provide a good experience the start-up time must be small. To achieve it, lmgrep had to be compiled with the native-image tool of the GraalVM. I’ve tried but the native-image doesn’t support Method Handles that Lucene uses. Some more hacking was needed. I was lucky when I’ve discovered a toy project where the blog search was implemented on AWS Lambda that was backed by Lucene which was compiled by the native-image tool. I’ve cloned the repo, mvnw install, then included the artefacts to the dependencies list, and lmgrep compiled with the native-image tool successfully.
Then the most complicated part was to prepare executable binaries for different operating systems. Plenty of CPU, RAM, VirtualBox with Windows and macOS virtual machines, and here we go.
Did I say how much I enjoyed trying to get stuff done on Windows? None at all. How come that multiple different(!) command prompts are needed to get GraalVM to compile an executable? Now I know that it would a lot better to suffer the pain and to set up the Github Actions pipeline to compile the binaries and upload them to release pages.
What is missing?
- The analysis pipeline is not as flexible as I’d like to (UPDATE 2021-04-24: implemented);
- Leverage the multicore CPUs by executing the search in parallel;
- Batch documents for matching;
- Let me know if any?
What would be cool ways to use lmgrep?
taillogs tolmgrepand raise alerts;- Give an alias for
lmgrepwith various options tailored for the code search (Java Example); - Why not expose sci script as TokenFilter?
- Why not ngrams token filter then the search would be resilient to the typing errors?
- Static website search, like AWS Lambda that has lmgrep and goes through all files on demand without upfront indexing.
Summary
lmgrep scratched my itch. It was exciting to get it working. I hope that you’ll also find it interesting and maybe useful. Give it a try, let me know how it was for you, and most importantly any feedback welcome on how to improve lmgrep.
References
- https://web.archive.org/web/20210116173133/https://swtch.com/~rsc/regexp/regexp4.html
- https://web.archive.org/web/20161018234331/http://www.techrepublic.com/article/graduating-from-grep-powerful-text-file-searching-with-isearch/
Footnotes
https://ideolalia.com/essays/composition-is-interpretation.html ↩︎
there is no necessity to split text files into lines, it is just to mimik how
grepoperates. ↩︎of course, the description is over-simplified, but it is accurate enough to get the overall idea. ↩︎