Entity Resolution with Opensearch/Elasticsearch
TL;DR
The entity resolution can be implemented as a search application and if the requirements are not too crazy then Opensearch/Elasticsearch is good enough.
Introduction
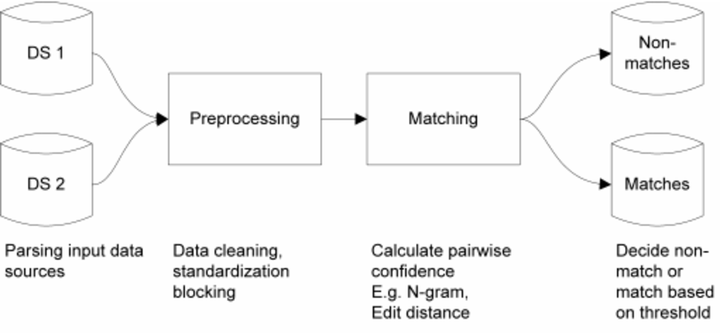
Say that our company have a curated registry of organizations (only organization names with the number of employees) conveniently indexed in the OpenSearch/Elasticsearch. Our employer acquired a direct competitor with their own nice little registry (only organization names with their addresses), and we were tasked to integrate the new registry with our old registry, i.e. to perform an entity resolution. Our task is to iterate through the new registry record by record and try to map them to our “Golden registry”. Unfortunately, the only overlapping data is organization names and our matching needs to be based mostly on the organization name. Let’s implement organization name matching by text similarity directly with Opensearch/Elasticsearch.
Requirements
Say that we were given these organization name similarity rules in the descending order of importance. Let’s have an example query “Apple” in mind as we go:
- Exact match, e.g. “Apple”
- Exact first word match, e.g. “Apple Computers”
- Exact not first word match, e.g. “Big Apple Company”
- Partial first word match - start, e.g. “Applesauce Company”
- Partial first word match - end, e.g. “Pineapple Manufacturing”
- Partial not first word match - end, e.g. “Canadian Bakeapple”
- Fuzzy, e.g. “Apply”
On top of that, we should be able to add other signals that could change the ordering, e.g. the number of employees: the more employees the matching organization has the higher its matching score.
“Applesauce Company” with 100 employees should be lower than “Pineapple Manufacturing” with 100000 employees despite that the rule of a partial first word match at the start has a higher name similarity than the partial not first word match at the end.
And yes, the entity resolution should be implemented only with features provided by Opensearch/Elasticsearch.
NOTE: the proposed solution is not production ready, use the examples wisely.
Additional notes for development
To make the development easier we also want:
- to know which rule matched for each hit we can leverage named queries feature (or try the highlighting1),
- give each rule a normalized score (TF-IDF is hard to normalize),
- matching of strings should be case-insensitive,
- Index (conveniently names
organizations) contains the sample organizations list (extracted from the requirements examples), - Work out the examples in Kibana/Dashboards,
The indexing of organizations can be done with this simple command:
PUT organizations/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Apple" }
{ "index" : { "_id" : "2" } }
{ "name" : "Apple Computers" }
{ "index" : { "_id" : "3" } }
{ "name" : "Big Apple Company" }
{ "index" : { "_id" : "4" } }
{ "name" : "Applesauce Company" }
{ "index" : { "_id" : "5" } }
{ "name" : "Pineapple Manufacturing" }
{ "index" : { "_id" : "6" } }
{ "name" : "Canadian Bakeapple" }
{ "index" : { "_id" : "7" } }
{ "name" : "Apply" }
Implementation Strategy
Let’s split the implementation into 3 parts:
- implement the organization name matching requirements,
- implement the scoring signal based on the number of employees,
- fine-tune the scoring function.
String Matching Implementation
In the following sections we’ll implement all string matching signals with the OpenSearch/Elasticsearch text analysis features.
I’ll work out each requirement in isolation.
For each rule we will define a subfield of the name attribute with an analyzer and a corresponding query clause.
Exact match
Exact matching is rather simple to implement, just use keyword datatype with a normalizer that lowercases the string.
Index configuration:
PUT organizations
{
"settings": {
"analysis": {
"normalizer": {
"lowercased_keyword": {
"type": "custom",
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"keyword_lowercased": {
"type": "keyword",
"normalizer": "lowercased_keyword"
}
}
}
}
}
}
Query:
GET organizations/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name.keyword_lowercased": {
"value": "Apple",
"_name": "exact_match"
}
}
},
"boost": 7
}
}
}
Matches exactly one organization:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 7.0,
"hits" : [
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "1",
"_score" : 7.0,
"_source" : {
"name" : "Apple"
},
"matched_queries" : [
"exact_match"
]
}
]
}
}
Exact first word match
With this requirement we want the query to match the first word of the organization name2.
We can implement the requirement by simply indexing only the first token.
To achieve it we could use the limit token filter.
Index configuration:
PUT organizations
{
"settings": {
"analysis": {
"analyzer": {
"standard_one_token_limit": {
"tokenizer": "standard",
"filter": [
"limit"
]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"first_token": {
"type": "text",
"analyzer": "standard_one_token_limit"
}
}
}
}
}
}
We leverage the fact that by default the limit token filter defaults max_token_count parameters to 1 token.
And we don’t need to define a new token filter (key damage to the keyboard, yay).
Query:
GET organizations/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name.first_token": {
"value": "Apple",
"_name": "Exact first word match"
}
}
},
"boost": 6
}
}
}
Hits:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 6.0,
"hits" : [
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "1",
"_score" : 6.0,
"_source" : {
"name" : "Apple"
},
"matched_queries" : [
"Exact first word match"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "2",
"_score" : 6.0,
"_source" : {
"name" : "Apple Computers"
},
"matched_queries" : [
"Exact first word match"
]
}
]
}
}
Note that not only “Apple Computers” matched but also “Apple” matched. This makes sense because “Apple” has only one word it is the first word.
If we wanted to exclude the “Apple” match we could combine the Exact first word match with the Exact match and construct a bool query, e.g.:
GET organizations/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"_name": "Exact first word match",
"must": [
{
"term": {
"name.first_token": {
"value": "Apple"
}
}
}
],
"must_not": [
{
"term": {
"name": {
"value": "Apple"
}
}
}
]
}
},
"boost": 6
}
}
}
For similar situations we could act similarly but let’s keep it simple.
Exact not first word match
E.g.: query “Apple” should match “Big Apple Company”.
The interesting bit is how to differentiate this rule from the Exact first word match?
As an implementation we could create a boolean query that filters out the first word match.
Another way to implement the is not to index the first word of the organization name.
A slight complication with this approach is that the query time analyzer should be different from
the index time analyzer to prevent the removal of the first (and probably the only) word from the query.
Let’s proceed with the second approach because I think it is more interesting.
PUT organizations
{
"settings": {
"analysis": {
"analyzer": {
"tokenized": {
"tokenizer": "standard",
"filter": [
"lowercase"
]
},
"tokenized_without_first_word": {
"tokenizer": "standard",
"filter": [
"remove_first_word",
"lowercase"
]
}
},
"filter": {
"remove_first_word": {
"type": "predicate_token_filter",
"script": {
"source": "token.position != 0"
}
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"tokenized_without_first_word": {
"type": "text",
"analyzer": "tokenized_without_first_word",
"search_analyzer": "tokenized"
}
}
}
}
}
}
Note, for the sake of simplicity for examples we assume only one word queries.
Query:
GET organizations/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"name.tokenized_without_first_word": {
"query": "Apple",
"_name": "Exact not first word match"
}
}
},
"boost": 5
}
}
}
Hits
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 6.0,
"hits" : [
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "3",
"_score" : 6.0,
"_source" : {
"name" : "Big Apple Company"
},
"matched_queries" : [
"Exact not first word match"
]
}
]
}
}
Partial first word match - start
E.g. Query “Apple” should match “Applesauce Company”. Probably we could get away with a simple prefix query, but if we want to make it fast for larger indices we should do edge n-grams token filter. The idea is to keep only this first word and then apply the edge n-gram token filter on it. Of course, query analyzer should be specified without edge n-gram token filter to prevent false hits from matching a couple of first characters from the query, e.g. query “Apps” would match “Apple” which we don’t want.
Index configuration:
PUT organizations
{
"settings": {
"analysis": {
"analyzer": {
"standard_first_token_limit": {
"tokenizer": "standard",
"filter": [
"limit",
"lowercase"
]
},
"standard_first_token_limit_edge_ngrams": {
"tokenizer": "standard",
"filter": [
"limit",
"1_10_edgegrams",
"lowercase"
]
}
},
"filter": {
"1_10_edgegrams": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 10
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"first_token_edge_ngram": {
"type": "text",
"analyzer": "standard_first_token_limit_edge_ngrams",
"search_analyzer": "standard_first_token_limit"
}
}
}
}
}
}
Here the max_ngram is set to 10 for no big reason, it really depends on your data.
Query:
GET organizations/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"name.first_token_edge_ngram": {
"query": "Apple",
"_name": "Partial first word match - start"
}
}
},
"boost": 4
}
}
}
Hits:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 4.0,
"hits" : [
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "1",
"_score" : 4.0,
"_source" : {
"name" : "Apple"
},
"matched_queries" : [
"Partial first word match - start"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "2",
"_score" : 4.0,
"_source" : {
"name" : "Apple Computers"
},
"matched_queries" : [
"Partial first word match - start"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "4",
"_score" : 4.0,
"_source" : {
"name" : "Applesauce Company"
},
"matched_queries" : [
"Partial first word match - start"
]
}
]
}
}
Note that “Apple” and “Apple Computers” also matched along the “Applesauce Company”. We could prevent matching the first two by doing the bool query with must_not match on the whole first token.
Partial first word match - end
E.g. Query “Apple” should match “Pineapple Manufacturing”. In other words, the query string should be the ending of the first word of the organization name. The idea is to take the first word, reverse it, apply edge n-grams, reverse those n-grams. The search time analyzer should not have an edge n-grams token filter.
Index configuration:
PUT organizations
{
"settings": {
"analysis": {
"analyzer": {
"standard_first_token_limit": {
"tokenizer": "standard",
"filter": [
"limit",
"lowercase"
]
},
"standard_one_token_limit_endings": {
"tokenizer": "standard",
"filter": [
"limit",
"lowercase",
"reverse",
"1_10_edgegrams",
"reverse"
]
}
},
"filter": {
"1_10_edgegrams": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 10
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"first_word_end_ngrams": {
"type": "text",
"analyzer": "standard_one_token_limit_endings",
"search_analyzer": "standard_first_token_limit"
}
}
}
}
}
}
Query:
GET organizations/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"name.first_word_end_ngrams": {
"query": "Apple",
"_name": "Partial first word match - end"
}
}
},
"boost": 3
}
}
}
Hits:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 3.0,
"hits" : [
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "1",
"_score" : 3.0,
"_source" : {
"name" : "Apple"
},
"matched_queries" : [
"Partial first word match - end"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "2",
"_score" : 3.0,
"_source" : {
"name" : "Apple Computers"
},
"matched_queries" : [
"Partial first word match - end"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "5",
"_score" : 3.0,
"_source" : {
"name" : "Pineapple Manufacturing"
},
"matched_queries" : [
"Partial first word match - end"
]
}
]
}
}
Partial not first word match - end
E.g. query “Apple” should match “Canadian Bakeapple”. The idea is to tokenize, lowercase, remove first word, reverse tokens, create edge n-grams, reverse back. Search time analyzer should not include edge n-grams.
Index configuration:
PUT organizations
{
"settings": {
"analysis": {
"analyzer": {
"standard_first_token_limit": {
"tokenizer": "standard",
"filter": [
"limit",
"lowercase"
]
},
"standard_remaining_token_endings": {
"tokenizer": "standard",
"filter": [
"remove_first_word",
"lowercase",
"reverse",
"1_10_edgegrams",
"reverse"
]
}
},
"filter": {
"1_10_edgegrams": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 10
},
"remove_first_word": {
"type": "predicate_token_filter",
"script": {
"source": "token.position != 0"
}
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"remaining_words_end_ngrams": {
"type": "text",
"analyzer": "standard_remaining_token_endings",
"search_analyzer": "standard_first_token_limit"
}
}
}
}
}
}
Query:
GET organizations/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"name.remaining_words_end_ngrams": {
"query": "Apple",
"_name": "Partial not first word match - end"
}
}
},
"boost": 2
}
}
}
Hits:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.0,
"hits" : [
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.0,
"_source" : {
"name" : "Big Apple Company"
},
"matched_queries" : [
"Partial not first word match - end"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "6",
"_score" : 2.0,
"_source" : {
"name" : "Canadian Bakeapple"
},
"matched_queries" : [
"Partial not first word match - end"
]
}
]
}
}
Fuzzy
E.g. query “Apple” should match “Apply”. It is pretty much the exact match but with some fuzziness allowed.
Index configuration:
PUT organizations
{
"settings": {
"analysis": {
"normalizer": {
"lowercased_keyword": {
"type": "custom",
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"keyword_lowercased": {
"type": "keyword",
"normalizer": "lowercased_keyword"
}
}
}
}
}
}
Query:
GET organizations/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"name": {
"query": "Apple",
"fuzziness": 1,
"_name": "fuzzy_1"
}
}
},
"boost": 1
}
}
}
Hits:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "Apple"
},
"matched_queries" : [
"fuzzy_1"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "Apply"
},
"matched_queries" : [
"fuzzy_1"
]
}
]
}
}
In some circumstances we might allow fuzziness set to more than 1.
Let’s combine the pieces together
Phew, that was pretty involved. Let’s combine the previous examples into one, so our requirements are satisfied.
Index configuration is constructed by merging analysis components and adding fields from all the examples:
PUT organizations
{
"settings": {
"analysis": {
"normalizer": {
"lowercased_keyword": {
"type": "custom",
"filter": [
"lowercase"
]
}
},
"filter": {
"1_10_edgegrams": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 10
},
"remove_first_word": {
"type": "predicate_token_filter",
"script": {
"source": "token.position != 0"
}
}
},
"analyzer": {
"standard_one_token_limit": {
"tokenizer": "standard",
"filter": [
"limit",
"lowercase"
]
},
"tokenized": {
"tokenizer": "standard",
"filter": [
"lowercase"
]
},
"tokenized_without_first_word": {
"tokenizer": "standard",
"filter": [
"remove_first_word",
"lowercase"
]
},
"standard_first_token_limit_edge_ngrams": {
"tokenizer": "standard",
"filter": [
"limit",
"lowercase",
"1_10_edgegrams"
]
},
"standard_first_token_limit": {
"tokenizer": "standard",
"filter": [
"limit",
"lowercase"
]
},
"standard_remaining_token_endings": {
"tokenizer": "standard",
"filter": [
"remove_first_word",
"lowercase",
"reverse",
"1_10_edgegrams",
"reverse"
]
},
"standard_one_token_limit_endings": {
"tokenizer": "standard",
"filter": [
"limit",
"lowercase",
"reverse",
"1_10_edgegrams",
"reverse"
]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"first_token": {
"type": "text",
"analyzer": "standard_one_token_limit"
},
"tokenized_without_first_word": {
"type": "text",
"analyzer": "tokenized_without_first_word",
"search_analyzer": "tokenized"
},
"first_token_edge_ngram": {
"type": "text",
"analyzer": "standard_first_token_limit_edge_ngrams",
"search_analyzer": "standard_first_token_limit"
},
"first_word_end_ngrams": {
"type": "text",
"analyzer": "standard_one_token_limit_endings",
"search_analyzer": "standard_first_token_limit"
},
"remaining_words_end_ngrams": {
"type": "text",
"analyzer": "standard_remaining_token_endings",
"search_analyzer": "standard_first_token_limit"
},
"keyword_lowercased": {
"type": "keyword",
"normalizer": "lowercased_keyword"
}
}
}
}
}
}
Here
The query is constructed from all the previous examples simply by adding constant score queries to the dis_max query:
GET organizations/_search
{
"query": {
"dis_max": {
"queries": [
{
"constant_score": {
"filter": {
"term": {
"name.keyword_lowercased": {
"value": "Apple",
"_name": "exact_match"
}
}
},
"boost": 7
}
},
{
"constant_score": {
"filter": {
"match": {
"name.first_token": {
"query": "Apple",
"_name": "Exact first word match"
}
}
},
"boost": 6
}
},
{
"constant_score": {
"filter": {
"match": {
"name.tokenized_without_first_word": {
"query": "Apple",
"_name": "Exact not first word match"
}
}
},
"boost": 5
}
},
{
"constant_score": {
"filter": {
"match": {
"name.first_token_edge_ngram": {
"query": "Apple",
"_name": "Partial first word match - start"
}
}
},
"boost": 4
}
},
{
"constant_score": {
"filter": {
"match": {
"name.first_word_end_ngrams": {
"query": "Apple",
"_name": "Partial first word match - end"
}
}
},
"boost": 3
}
},
{
"constant_score": {
"filter": {
"match": {
"name.remaining_words_end_ngrams": {
"query": "Apple",
"_name": "Partial not first word match - end"
}
}
},
"boost": 2
}
},
{
"constant_score": {
"filter": {
"match": {
"name": {
"query": "Apple",
"fuzziness": 1,
"_name": "fuzzy_1"
}
}
},
"boost": 1
}
}
]
}
}
}
Finally, the list of organizations ranked by the name similarity:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 7,
"relation" : "eq"
},
"max_score" : 7.0,
"hits" : [
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "1",
"_score" : 7.0,
"_source" : {
"name" : "Apple"
},
"matched_queries" : [
"exact_match",
"Partial first word match - end",
"Partial first word match - start",
"Exact first word match",
"fuzzy_1"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "2",
"_score" : 6.0,
"_source" : {
"name" : "Apple Computers"
},
"matched_queries" : [
"Partial first word match - end",
"Partial first word match - start",
"Exact first word match"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "3",
"_score" : 5.0,
"_source" : {
"name" : "Big Apple Company"
},
"matched_queries" : [
"Exact not first word match",
"Partial not first word match - end"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "4",
"_score" : 4.0,
"_source" : {
"name" : "Applesauce Company"
},
"matched_queries" : [
"Partial first word match - start"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "5",
"_score" : 3.0,
"_source" : {
"name" : "Pineapple Manufacturing"
},
"matched_queries" : [
"Partial first word match - end"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "6",
"_score" : 2.0,
"_source" : {
"name" : "Canadian Bakeapple"
},
"matched_queries" : [
"Partial not first word match - end"
]
},
{
"_index" : "organizations",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "Apply"
},
"matched_queries" : [
"fuzzy_1"
]
}
]
}
}
Nice, from the most similar “Exact match” all the way down to the “fuzzy” matches.
I believe this post got a bit too long to continue working out the remaining requirements. I’ll finish the developments in the future post. Also, it shouldn’t be too hard to load bigger dataset to test our entity resolution algorithm, something like Companies House registry with some real world data.
Summary
I hope this exercise was interesting. To sum up:
- I’ve demonstrated how to do the text analysis tricks that would shape the organization name string according to the requirements.
- As a way to normalize search scores I’ve used the
constant_scorequery. To come up with this trick is not very obvious because Elasticsearch scoring by default is unbounded due to text statistics and therefore not very well suited to satisfy the requirements of matching semi structured short strings such ar organization names. - Another neat trick was to use the
dis_maxquery to calculate the score by taking only the most significant similarity signal. In this way we’ve prevented the situations where less similar matches would go up because they matched several less significant similarity rules and their score were added up. - Also, by using
_nameparameters for each query clause we get which similarity rules matched despite the fact that we’ve took the score of the highest scoring similarity rule. These flags might be used for further rescoring in your application.
In case of any comments or questions don’t hesitate to leave comments under this Github issue.
Footnotes
Another approach would be to use hits highlighting. ↩︎
Of course, this is a bit unrealistic because organization name might very well contain more than one word. A hint on how to implement the same requrements for two word organization names would be to use shingles. ↩︎